2024-03-16
I’ve been learning about LLMs a bit. After watching a recent video about LLM tokenization by Andrej Karpathy a thought appeared in my mind.
Namely: I think it might be promising to investigate Jevko-based formats as an efficient (cheap in terms of tokens) alternative to JSON/YAML/etc. for interacting with LLMs in a structured way.
How so? Let’s take a look at the relevant fragment of the video:
Here is the transcript:
[D]ifferent kinds of formats and different representations and different languages and so on might be more or less efficient with GPT tokenizers or any tokenizers for any other LLM for that matter.
So for example JSON is actually really dense in tokens and YAML is a lot more efficient in tokens.
So for example these are the same in JSON and in YAML.
The JSON is 116 and the YAML is 99 so quite a bit of an improvement.
And so in the token economy where we are paying per token in many ways and you are paying in the context length and you’re paying in dollar amount for the cost of processing all this kind of structured data when you have to.
So prefer to use YAMLs over JSONs and in general kind of like the tokenization density is something that you have to sort of care about and worry about at all times and try to find efficient encoding schemes and spend a lot of time in Tiktokenizer and measure the different token efficiencies of different formats and settings and so on…
Emphasis mine.
Now let’s create an equivalent piece of data in a Jevko-based format and see how that compares.
Here is one possibility, using formatting similar to the JSON example:
product[
type[T-Shirt]
price[20.00]
sizes[[S][M][L]]
reviews[
[ username[user1] rating[4] created_at[2023-04-19T12:30:00Z] ]
[ username[user2] rating[5] created_at[2023-05-02T15:00:00Z] ]
]
]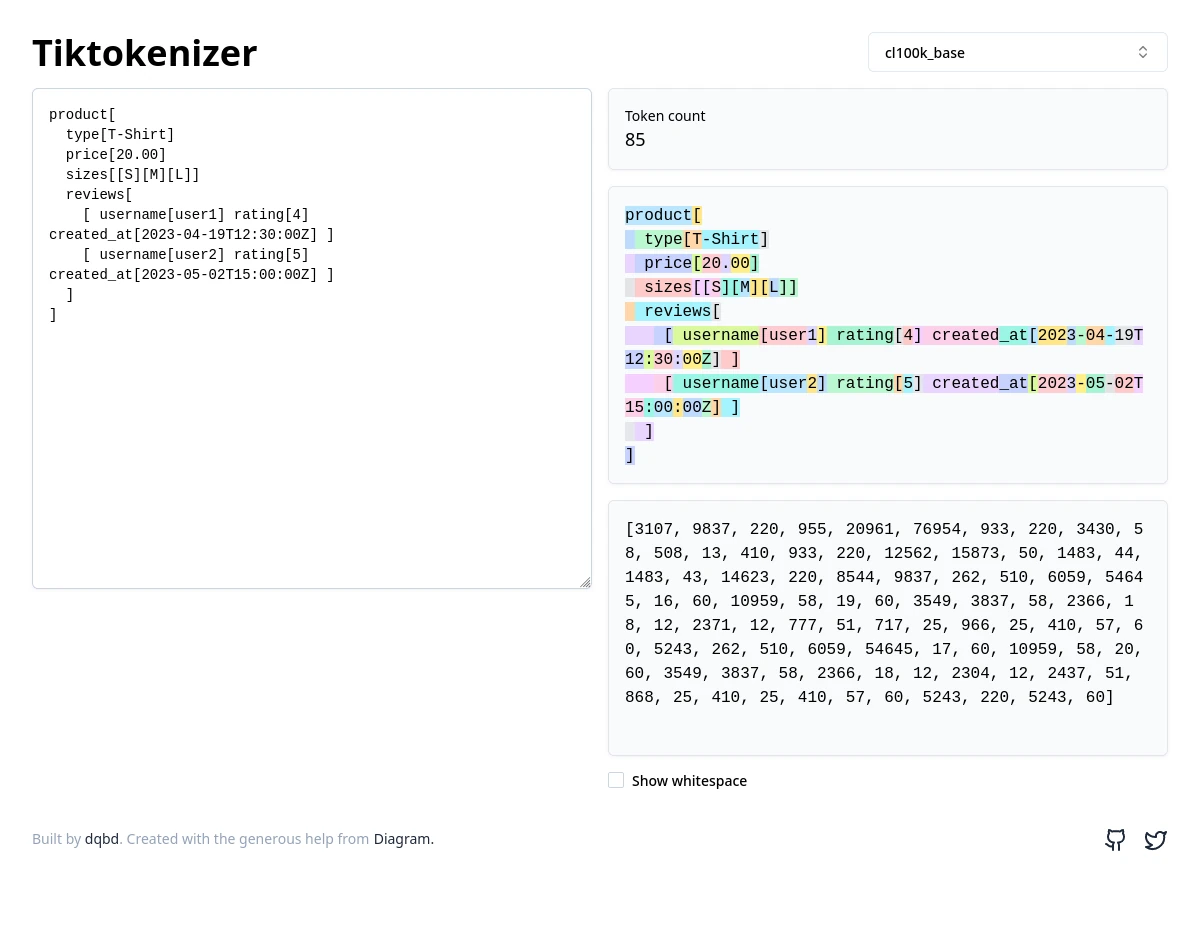
Down to 85. I think that qualifies as “quite a bit of an improvement”.
We can actually remove all the whitespace though:
product[type[T-Shirt]price[20.00]sizes[[S][M][L]]reviews[[username[user1]rating[4]created_at[2023-04-19T12:30:00Z]][username[user2]rating[5]created_at[2023-05-02T15:00:00Z]]]]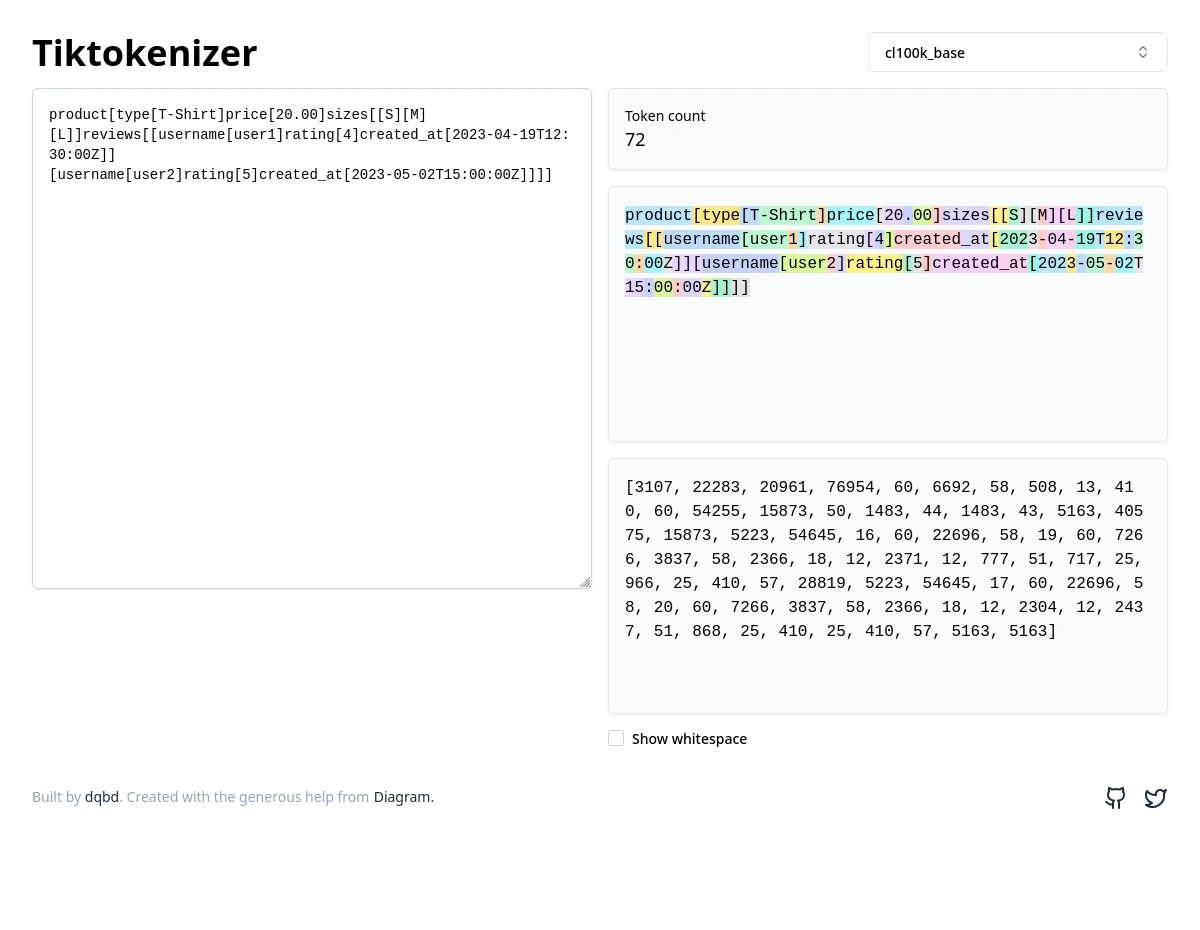
Down to 72. Not bad, eh?
Let’s see how all these compare:
JSON: 116 (100 %)
YAML: 99 (85 %)
Jevko #1: 85 (73 %)
Jevko #2: 72 (62 %)See also this old comparison of a Jevko-based format vs XML/JSON/EDN/S-expr.
Now I don’t know enough about LLMs yet to tell if this is a good lead. So I’m putting this idea out there in the hope that somebody who knows a bit more can tell me.
If you are that somebody, write me an email at
tao at xtao.org. If you know a somebody, I’d appreciate if
you send them a link to this article. Thanks!

If you like, you can support my work with a small donation.
 or
or


Thank you!

![[^Jevko]](/jevko.svg)